DeepMind's MuZero teaches itself how to win at Atari, chess, shogi, and Go
Por um escritor misterioso
Descrição
In a preprint paper, researchers at Alphabet's DeepMind detail MuZero, an algorithm that effectively teaches itself how to play Atari and board games.
Will AlphaZero become smarter and smarter forever, if it plays chess against itself for unlimited times? - Quora

DeepMind's MuZero picks up the rules of games as it plays

N] No rules, no problem: DeepMind's MuZero masters games while learning how to play them : r/MachineLearning

Deep Learning, DeepMind's MuZero and AlphaFold, OpenAI's GPT3, Artificial General Intelligence (AGI), by Madhav Kunal

From AlphaGo to MuZero - Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model

AlphaGo - Google DeepMind

Julian Schrittwieser – MuZero, Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model

Want to Know the AI Lingo? Learn the Basics, From NLP to Neural Networks - WSJ
MuZero: Mastering Go, chess, shogi and Atari without rules - Google DeepMind
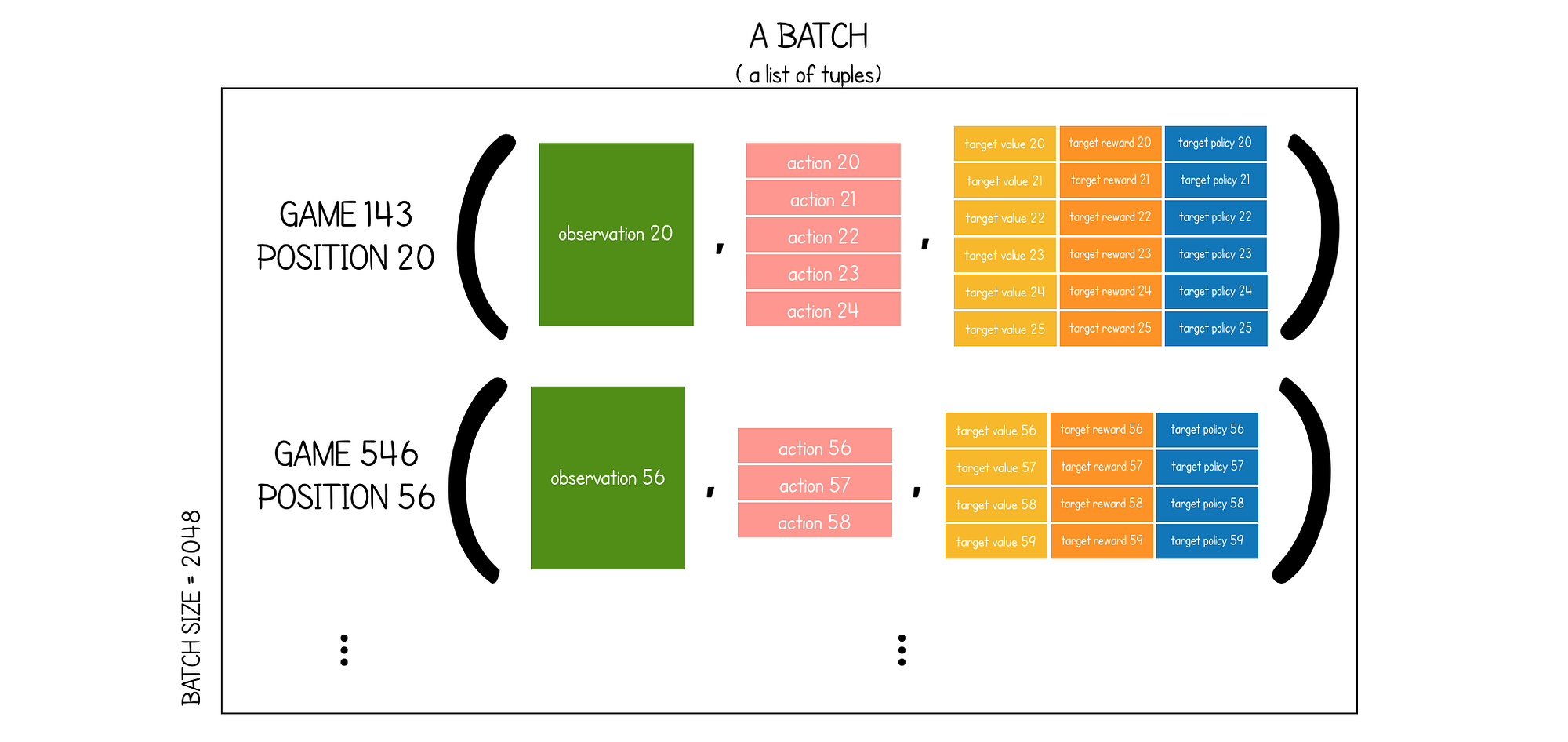
MuZero: The Walkthrough (Part 3/3), by David Foster, Applied Data Science

Alphazero :: Computer-bridge1

MuZero - Wikipedia

DeepMind's New AI Masters Games Without Even Being Taught the Rules - IEEE Spectrum
de
por adulto (o preço varia de acordo com o tamanho do grupo)